
 PhD student
PhD studentI'm a PhD student in the Department of Applied Psychology and Human Development at the University of Toronto. I work under the supervision of Dr. Feng Ji in the Psychometrics and Responsible AI Lab.
My research harnesses advances in machine learning, statistics, and quantitative methodology to tackle pressing questions in psychological and educational measurement, with a particular emphasis on the convergence of psychometrics and artificial intelligence.
Warning
Problem: The current name of your GitHub Pages repository ("Solution: Please consider renaming the repository to "
http://".
However, if the current repository name is intended, you can ignore this message by removing "{% include widgets/debug_repo_name.html %}" in index.html.
Action required
Problem: The current root path of this site is "baseurl ("_config.yml.
Solution: Please set the
baseurl in _config.yml to "Education
-
University of TorontoDept. of Applied Psychology and Human Development
Ph.D. StudentSep. 2024 - present -
 University of OxfordMSc. in Statistical Science, DistinctionOct. 2023 - Sep. 2024
University of OxfordMSc. in Statistical Science, DistinctionOct. 2023 - Sep. 2024 -
 The Chinese University of Hong Kong, ShenzhenBSc. in Applied Mathematics, First ClassSep. 2019 - May 2023
The Chinese University of Hong Kong, ShenzhenBSc. in Applied Mathematics, First ClassSep. 2019 - May 2023
Experience
-
The Chinese University of Hong Kong, ShenzhenResearch Assistant, Advisor: Dr. Jinbo HeMay. 2022 - present
-
 Shenzhen Research Institute of Big DataResearch AssistantJun. 2021 - Aug. 2022
Shenzhen Research Institute of Big DataResearch AssistantJun. 2021 - Aug. 2022
Honors & Awards
-
Connaught International Scholarship for Doctoral Students (2025-2029)2024
-
Schwartz Reisman Institute for Technology and Society 2025-26 Graduate Fellow2025
Selected Publications (view all )

Federated Item Response Models: A Gradient-driven Privacy-preserving Framework for Distributed Psychometric Estimation
Biying Zhou*, Nanyu Luo*, Feng Ji#
Submitted to Psychometrika Under review. 2025
Item Response Theory (IRT) models are widely used to estimate respondents' latent abilities and calibrate item difficulty. Traditional IRT estimation typically requires centralizing all raw responses, raising privacy and governance concerns. We introduce Federated Item Response Theory (FedIRT), a framework that enables distributed calibration of standard IRT models without transferring individual-level data, thereby preserving confidentiality while retaining statistical efficiency. To provide formal protection, we further develop FedIRT-DP, a user-level differentially private extension. Each site computes per-student gradients, clips them to a fixed norm, and shares only masked sums; the server adds calibrated Gaussian noise and performs MAP updates. This yields an auditable (ε, δ) guarantee at the student level and a single, tunable privacy-utility trade-off via the clipping bound and noise scale. The same mechanism improves robustness to extreme response rows (e.g., all-zeros/ones). Across simulations, FedIRT matches the accuracy of centralized estimators from popular `R` packages while avoiding data pooling; FedIRT-DP achieves comparable accuracy under stronger privacy and exhibits superior robustness to contamination. An empirical study on a real exam dataset demonstrates practical viability and consistent item and site-effect estimates. To facilitate adoption, we release an open-source `R` package, `FedIRT`, implementing the two-parameter logistic (2PL) and partial credit models (PCM) with federated and differentially private training.
Federated Item Response Models: A Gradient-driven Privacy-preserving Framework for Distributed Psychometric Estimation
Biying Zhou*, Nanyu Luo*, Feng Ji#
Submitted to Psychometrika Under review. 2025
Item Response Theory (IRT) models are widely used to estimate respondents' latent abilities and calibrate item difficulty. Traditional IRT estimation typically requires centralizing all raw responses, raising privacy and governance concerns. We introduce Federated Item Response Theory (FedIRT), a framework that enables distributed calibration of standard IRT models without transferring individual-level data, thereby preserving confidentiality while retaining statistical efficiency. To provide formal protection, we further develop FedIRT-DP, a user-level differentially private extension. Each site computes per-student gradients, clips them to a fixed norm, and shares only masked sums; the server adds calibrated Gaussian noise and performs MAP updates. This yields an auditable (ε, δ) guarantee at the student level and a single, tunable privacy-utility trade-off via the clipping bound and noise scale. The same mechanism improves robustness to extreme response rows (e.g., all-zeros/ones). Across simulations, FedIRT matches the accuracy of centralized estimators from popular `R` packages while avoiding data pooling; FedIRT-DP achieves comparable accuracy under stronger privacy and exhibits superior robustness to contamination. An empirical study on a real exam dataset demonstrates practical viability and consistent item and site-effect estimates. To facilitate adoption, we release an open-source `R` package, `FedIRT`, implementing the two-parameter logistic (2PL) and partial credit models (PCM) with federated and differentially private training.
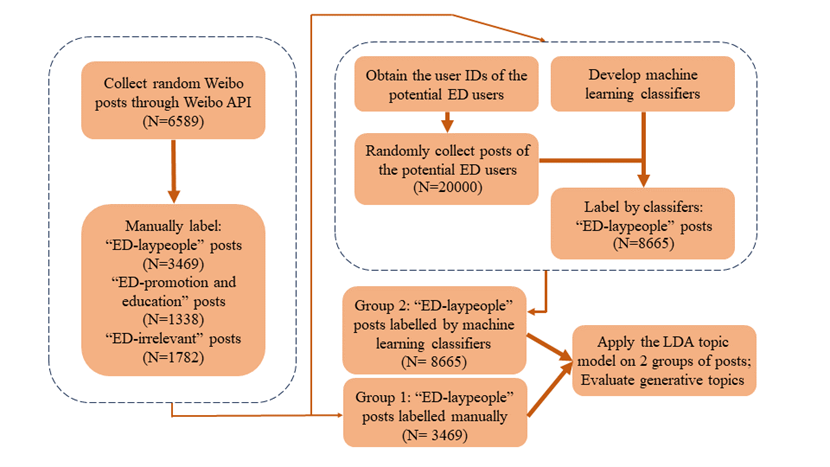
Identifying and Characterizing Eating Disorder Discourse on Chinese Social Media: A Machine Learning Approach
Yuchen Zhang*, Nanyu Luo*, Xiaoya Zhang, Feng Ji#, Jinbo He
Submitted to Journal of Eating Disorders Under review. 2025
Background Eating disorders (EDs) are severe psychiatric conditions with high mortality and substantial medical complications. In China, underdiagnosis and low treatment engagement hinder timely intervention. Social media platforms provide a naturalistic lens into ED-related experiences, yet research on Chinese-language data remains scarce. Advances in machine learning (ML) and deep learning (DL) offer new opportunities to identify and characterize such ED discourse, informing the development of scalable detection methods and culturally tailored prevention and intervention strategies in the Chinese context. Methods We collected ED-related posts from Weibo via keyword-based API searches and manually annotated them into three groups: irrelevant, promotional/educational content, and layperson posts. Five ML/DL methods, including Convolutional Neural Networks (CNNs), Random Forests, XGBoost, Support Vector Machines (SVMs), and Logistic Regression, were trained to identify ED-related posts in a two-stage framework: (1) filtering out irrelevant posts and (2) distinguishing promotional/educational posts from layperson posts. Classifier performance was evaluated on additional posts from the same users. Latent Dirichlet Allocation (LDA) was applied to the layperson subset to extract underlying ED-related themes. Results CNN consistently outperformed other models, achieving high F1-scores in both classification stages (0.87 and 0.98, respectively). Topic modelling revealed five themes: restrictive symptomatology and physical distress, binge eating and body-health concerns, relapse and coping narratives, emotional venting, and chronic ED patterns with identity impact. Conclusions This study demonstrates that CNN-based classification combined with topic modeling provides a scalable framework for detecting ED-related discourse on Chinese social media. Beyond methodological advances in non-English NLP, the findings highlight culturally specific symptom expressions and psychosocial concerns, offering novel insights for public health surveillance. These insights can inform the development of early detection tools and culturally sensitive interventions to address the unmet needs of individuals with EDs in China.
Identifying and Characterizing Eating Disorder Discourse on Chinese Social Media: A Machine Learning Approach
Yuchen Zhang*, Nanyu Luo*, Xiaoya Zhang, Feng Ji#, Jinbo He
Submitted to Journal of Eating Disorders Under review. 2025
Background Eating disorders (EDs) are severe psychiatric conditions with high mortality and substantial medical complications. In China, underdiagnosis and low treatment engagement hinder timely intervention. Social media platforms provide a naturalistic lens into ED-related experiences, yet research on Chinese-language data remains scarce. Advances in machine learning (ML) and deep learning (DL) offer new opportunities to identify and characterize such ED discourse, informing the development of scalable detection methods and culturally tailored prevention and intervention strategies in the Chinese context. Methods We collected ED-related posts from Weibo via keyword-based API searches and manually annotated them into three groups: irrelevant, promotional/educational content, and layperson posts. Five ML/DL methods, including Convolutional Neural Networks (CNNs), Random Forests, XGBoost, Support Vector Machines (SVMs), and Logistic Regression, were trained to identify ED-related posts in a two-stage framework: (1) filtering out irrelevant posts and (2) distinguishing promotional/educational posts from layperson posts. Classifier performance was evaluated on additional posts from the same users. Latent Dirichlet Allocation (LDA) was applied to the layperson subset to extract underlying ED-related themes. Results CNN consistently outperformed other models, achieving high F1-scores in both classification stages (0.87 and 0.98, respectively). Topic modelling revealed five themes: restrictive symptomatology and physical distress, binge eating and body-health concerns, relapse and coping narratives, emotional venting, and chronic ED patterns with identity impact. Conclusions This study demonstrates that CNN-based classification combined with topic modeling provides a scalable framework for detecting ED-related discourse on Chinese social media. Beyond methodological advances in non-English NLP, the findings highlight culturally specific symptom expressions and psychosocial concerns, offering novel insights for public health surveillance. These insights can inform the development of early detection tools and culturally sensitive interventions to address the unmet needs of individuals with EDs in China.

Fitting Item Response Theory Models Using Deep Learning Computational Frameworks
Nanyu Luo, Yuting Han, Jinbo He, Xiaoya Zhang, Feng Ji#
Submitted to JEBS Under review. 2025
PyTorch and TensorFlow are two widely adopted, modern deep learning frameworks that offer comprehensive computational libraries for developing deep learning models. In this study, we illustrate how to leverage these computational platforms to estimate a class of widely used psychometric models—dichotomous and polytomous Item Response Theory (IRT) models—along with their multidimensional extensions. Simulation studies demonstrate that the parameter estimates exhibit low mean squared error and bias. An empirical case study further illustrates how these two frameworks compare with other popular software packages in applied settings. We conclude by discussing the potential of integrating modern deep learning tools and perspectives into psychometric research.
Fitting Item Response Theory Models Using Deep Learning Computational Frameworks
Nanyu Luo, Yuting Han, Jinbo He, Xiaoya Zhang, Feng Ji#
Submitted to JEBS Under review. 2025
PyTorch and TensorFlow are two widely adopted, modern deep learning frameworks that offer comprehensive computational libraries for developing deep learning models. In this study, we illustrate how to leverage these computational platforms to estimate a class of widely used psychometric models—dichotomous and polytomous Item Response Theory (IRT) models—along with their multidimensional extensions. Simulation studies demonstrate that the parameter estimates exhibit low mean squared error and bias. An empirical case study further illustrates how these two frameworks compare with other popular software packages in applied settings. We conclude by discussing the potential of integrating modern deep learning tools and perspectives into psychometric research.
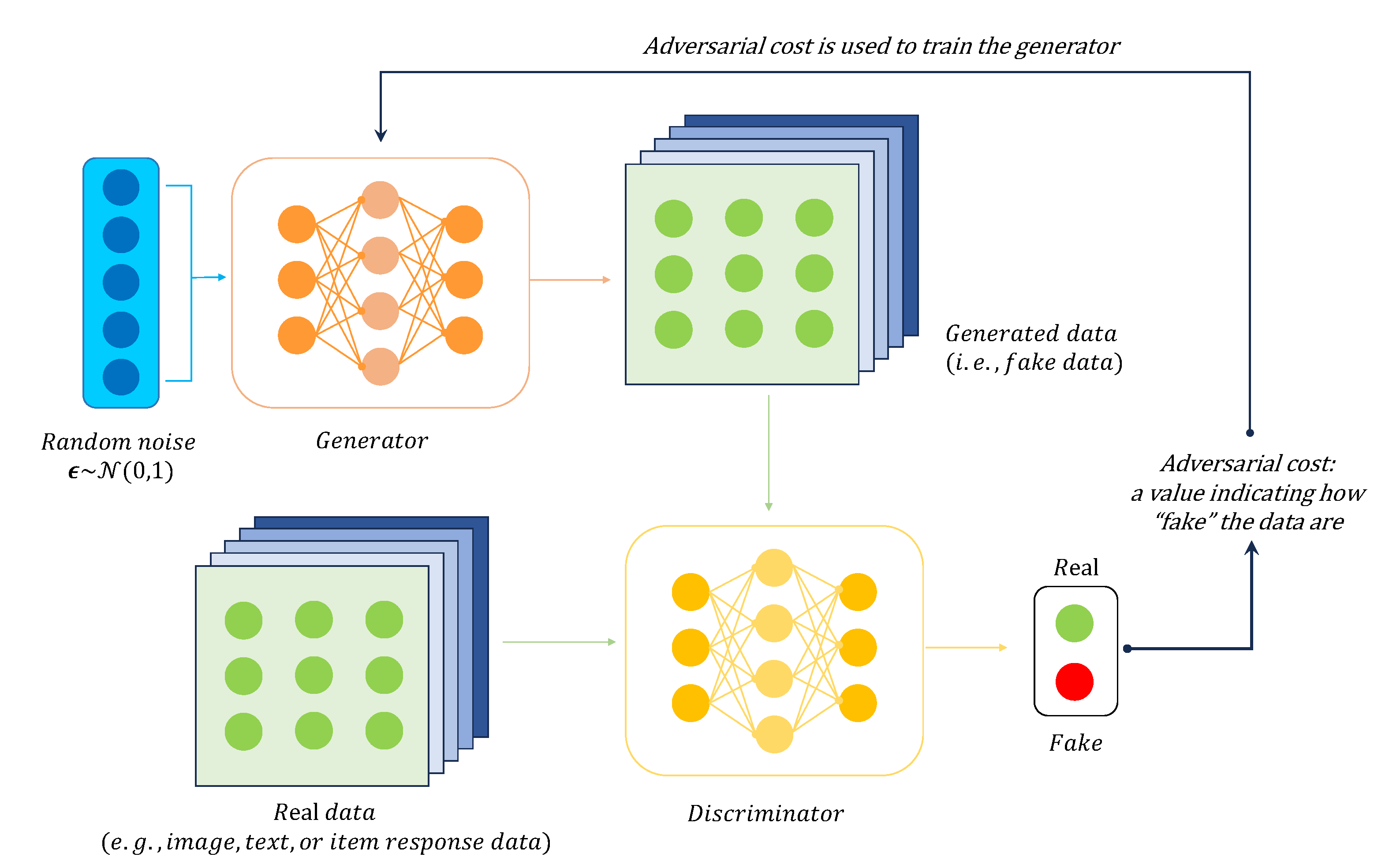
Generative Adversarial Networks for High-Dimensional Item Factor Analysis: A Deep Adversarial Learning Algorithm
Nanyu Luo, Feng Ji#
Psychometrika 2025
Advances in deep learning and representation learning have transformed item factor analysis (IFA) in the item response theory (IRT) literature by enabling more efficient and accurate parameter estimation. Variational autoencoders (VAEs) are widely used to model high-dimensional latent variables in this context, but the limited expressiveness of their inference networks can still hinder performance. We introduce adversarial variational Bayes (AVB) and an importance-weighted extension (IWAVB) as more flexible inference algorithms for IFA. By combining VAEs with generative adversarial networks (GANs), AVB uses an auxiliary discriminator network to frame estimation as a two-player game and removes the restrictive standard normal assumption on the latent variables. Theoretically, AVB and IWAVB can achieve likelihoods that match or exceed those of VAEs and importance-weighted autoencoders (IWAEs). In exploratory analyses of empirical data, IWAVB attained higher likelihoods than IWAE, indicating greater expressiveness. In confirmatory simulations, IWAVB achieved comparable mean-square error in parameter recovery while consistently yielding higher likelihoods, and it clearly outperformed IWAE when the latent distribution was multimodal. These findings suggest that IWAVB can scale IFA to complex, large-scale, and potentially multimodal settings, supporting closer integration of psychometrics with modern multimodal data analysis.
Generative Adversarial Networks for High-Dimensional Item Factor Analysis: A Deep Adversarial Learning Algorithm
Nanyu Luo, Feng Ji#
Psychometrika 2025
Advances in deep learning and representation learning have transformed item factor analysis (IFA) in the item response theory (IRT) literature by enabling more efficient and accurate parameter estimation. Variational autoencoders (VAEs) are widely used to model high-dimensional latent variables in this context, but the limited expressiveness of their inference networks can still hinder performance. We introduce adversarial variational Bayes (AVB) and an importance-weighted extension (IWAVB) as more flexible inference algorithms for IFA. By combining VAEs with generative adversarial networks (GANs), AVB uses an auxiliary discriminator network to frame estimation as a two-player game and removes the restrictive standard normal assumption on the latent variables. Theoretically, AVB and IWAVB can achieve likelihoods that match or exceed those of VAEs and importance-weighted autoencoders (IWAEs). In exploratory analyses of empirical data, IWAVB attained higher likelihoods than IWAE, indicating greater expressiveness. In confirmatory simulations, IWAVB achieved comparable mean-square error in parameter recovery while consistently yielding higher likelihoods, and it clearly outperformed IWAE when the latent distribution was multimodal. These findings suggest that IWAVB can scale IFA to complex, large-scale, and potentially multimodal settings, supporting closer integration of psychometrics with modern multimodal data analysis.